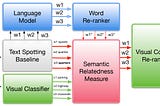
Ahmed SabirSimilarity to Probability — Part I: Visual Word Embedding for OCR Post CorrectionIn this post, I will revisit in more detail our previous work that uses human-inspired likelihood revision or similarity to probability…Nov 3, 2022Nov 3, 2022
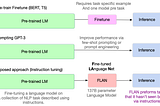
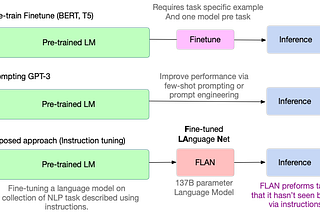
Ahmed SabirICRL2022 — Interesting PapersIn this short post blog, I will highlight some interesting ideas that presented in ICLR 2022 both in 🖼️ Computer Vision and 📖 Natural…May 1, 2022May 1, 2022
Ahmed SabirPaper Summary: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language…In this blog post, I will discuss this vision and language paper BLIP: Bootstrapping Language-Image Pre-training for Unified…Mar 28, 2022Mar 28, 2022
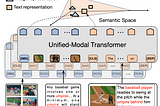
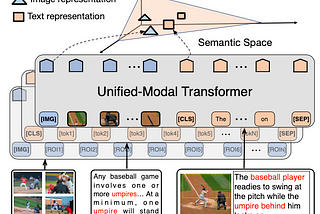
Ahmed SabirPaper Summary: UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal…In this post, I will outline some important aspects of this language and vision paper. In a bird’s view, the authors tried to unify…Mar 9, 2022Mar 9, 2022
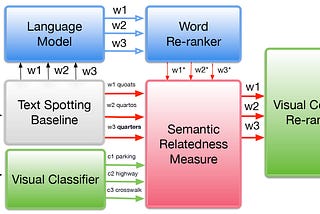
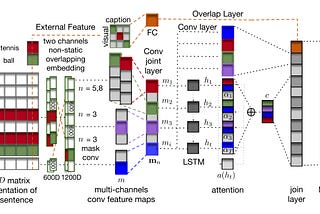
Ahmed SabirAn application for Semantic Relatedness: Post OCR CorrectionIn this post, I will discuss our work that uses semantic relatedness measure, as a post-processing based method, to improve text…Feb 20, 2022Feb 20, 2022