Paper Summary: BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
In this blog post, I will discuss this vision and language paper BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, which is the newest Feb-2022 model and current state-of-the-art in different languages and visions tasks. First, let me show you how BLIP can generate a more accurate caption than previous state-of-the-art models with some examples in the caption generation task.

Transformer (Vaswani et al., 2017): (B4: 38.7)caption: a dog sitting in a basket with shoesAoANet (Huang et al., 2019): (B4: 38.9)caption: a stuffed dog laying in a pile of shoesOSCAR_Large (Li et al., 2020):(B4: 37.4)caption: a close up of a dog laying in a basket------ This work BLIP_Large (Li et al., 2022): (B@4: 39.7)caption Beam search: a dog laying on top of a pile of shoes
caption Nucleus Sampling: a dog sleeping inside of a wire basketHuman annotation: a small dog is curled up on top of the shoes
Please refer to their
- Web demo here (official)
- Colab demo here, (official)
- Colab here for multiple images with BLIP_Large, with Beam Search and Nucleus Sampling.
- Github Modified demo here that runs locally in your machine. (including BLIP 2 demo)
- Youtube review — Yannic Kilcher ฿.
Next, I will discuss the model architecture:
Model Architecture
The model uses Vision Transformer ViT (Dosovitskiy et al., 2021) ฿ which divides the input image into patches and encodes them as a sequence of embedding with addition to [CLS] token to represent the globe image feature. As the authors mentioned ViT uses less computation cost and is a straightforward method, and is being adopted by recent methods.
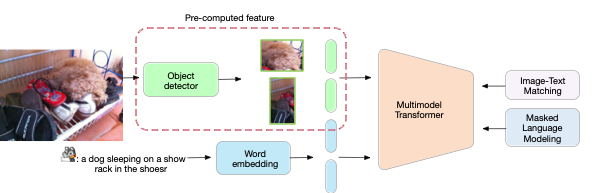
Note that as shown in Figure 2 (below) most Transformer caption generation* and pre-trained language and vision** based approaches use pre-computed feature bounding box*** which makes these models not friendly for any domain adaptation and computationally expensive. For example, for every new image, the model needs to pre-compute this external feature.
Caption Transformer* (Huang et al., 2019, Cornia et al., 2020) and pre-trained language and vision** model (OSCAR (Li et al., 2020), UNITER (Chen et al., 2020b)). ***Pre-compute features such as Faster R-CNN (Ren et al., 2016) and Buttom-up (Anderson et al., 2018).
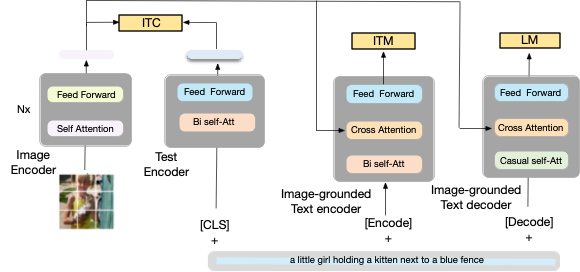
To be able to train/pre-trained such a model for understanding and generation tasks, the authors proposed a multimodel Mixture of Encoder and Decoder that can integrate three functionalities as shown in figure 3 (below):
(1) Text Encoder (left), (2) Image grounded Text Encoder (middle), and (3) Decoder (right).
Now, let me discuss each block in more detail:
(1) Unimodal encoder. The model encodes text and image as shown in Figure 4 (below). The text encoder is the same as BERT i.e., Mask Language Model (Devlin et al., 2019) with a [CLS] token to append the beginning of the text input to summarize the sentence.
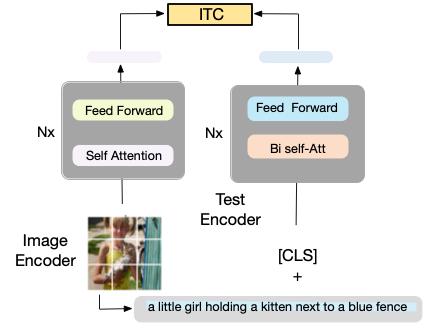
The Unimodal encoder uses Image-Text Contrastive Loss (ITC). The idea is to align the two feature text and image in the semantic space. In particular, as this work relies on contractive learning, the ITC loss encourages positive image-text pairs to have similar representations in contrast to the negative pairs. This observation, an effective objective for improving vision and language understanding, is already been used in recent work CLIP (Radford et al., 2021; Li et al., 2021a). The ITC loss (Li et al., 2021a) ฿ uses the soft labels as training targets to account for the potential positive in the negative pairs.
The ITC loss was proposed by the same authors. As the authors mentioned in their previous work, the ITC loss serves three purposes: (1) it aligns the image features and the text features, making it easier for the multimodal encoder to perform cross-modal learning; (2) it improves the unimodal encoders to better understand the semantic meaning of images and texts; (3) it learns a common low-dimensional space to embed images and texts, which enables the image-text matching objective to find more informative samples through the contrastive hard negative mining.
In general, the proposed model called ALing BEfore Fuse ALBEF uses three losses (1) image-text contrastive loss (ITC), (2) masked language modeling loss (MLM), and (3) image-text matching loss (ITM) with momentum distillation to learn SOTA representations, which we will discuss in more detail as well in this blog post.
(2) Image-grounded text encoder. The encoder relies on an additional cross-attention (CA) layer (between the self-attention (SA) layer and the feed-forward network (FFN) for each transformer block of the text encoder) as shown in Figure 6 below in orange color. The encoder is a task-specific to encode the multimodal representation of the image-text pair.

The Image-grounded text encoder uses Image-Text Matching Loss (ITM). The ITM aims to capture the fine-grained grounded alignment between vision and language. The ITM is a binary classification task, where the model predicts the match positive and unmatch negative pair (i.e., the model is acting as a filter). Note that, to increase the negative pair, a hard negative mining strategy is used via contrastive similarity to match the most similar negative pair (Li et al. 2021a).
(3) Image-grounded text decoder. This decoder uses causal self-attention (as shown in Figure 7 in green color) layers instated of bi-directional self-attention. The causal self-attention is used to predict the next token as in the generation task.

The Image-grounded text decoder employs Language Modeling Loss (LM). It activates the image grounded text decoder with the aim of generating textual descriptions given an image. The LM loss is trained to maximize the likelihood of the text in an autoregressive manner. This Mask language Modeling loss has already shown significant results in different models such as visual and language pre-training, to generate coherent captions.
In order to perform efficient pre-training while leveraging multi-task learning as explained above:
- The text encoder and text decoder share all parameters except for the self-attention layers (Figure 3 same color indicate shared parameters). The reason is that the differences between the encoding and decoding tasks are best captured by the self-attention layers.
- The encoder employs bi-directional self-attention to build representations for the current input tokens,
- while the decoder employs causal self-attention to predict the next tokens.
Therefore sharing these layers can improve training efficiency while benefiting from multi-task learning.
CapFilt
Due to the high cost of human annotation, there are only limited high-quality human-annotated image pairs like COCO caption e.g., COCO (Lin et al., 2014). Most recent work (Li et al., 2021a) relies heavily on noisy data extracted from the web — web scraping (WS). The WS process is the fastest way to collect a larger number of image-text pairs without the need for humans in the loop. However, as the data is noisy, e.g, wrong description of an image as shown in Figure 8 (Image) below, it affects the learning vision-language alignment signal.

To tackle this problem the authors propose Captioning and Filtering (CapFilt), a new method to improve the quality of the text corpus. Figure 9 gives an illustration of CapFilt. It introduces two modules:
- A captioner to generate synthetic captions given web images.
- A filter to remove noisy image-text pairs.
Both the captioner and the filter are initialized from the same pre-trained MED model (explained above), and fine-tuned individually on the high quality human-annotated COCO dataset (the human data will be used as reference).
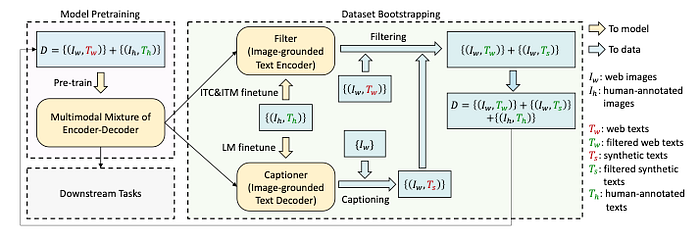
Specifically, as shown in the Figure 9 above the captioner is an image-grounded text decoder (see Figure 7). It is fine-tuned with the LM objective to decode texts given images.
(1) Given the web images I_w, the captioner generates synthetic captions T_s with one caption per image.
(2) The filter is an image-grounded text encoder. It is fine-tuned with the ITC and ITM objectives to learn whether a text matches an image. The filter removes noisy texts in both the original web texts T_w and the synthetic texts T_s, where a text is considered to be noisy if the ITM head predicts it as unmatched to the image.
(3) Finally, all the above are combined (i.e., the filtered image-text pairs with the human-annotated pairs) to form a new dataset that will be used to pre-train a new model.
Pre-trained model details:
- The image transformer is initialized from ViT pre-trained on ImageNet (Touvron et al., 2020; Dosovitskiy et al., 2021),
- The text transformer is initialized from BERT_base (Devlin et al., 2019).
There are two variants of ViTs: ViT-B/16 and ViT-L/16.
- AdamW (Loshchilov & Hutter, 2017) is used as an optimizer with a weight decay of 0.05. The learning rate is warmed-up to 3e-4 (ViT-B) / 2e-4 (ViT-L) and decayed linearly with a rate of 0.85.
- A random image crop of resolution 224 × 224 is used during pre-training. However, a higher image resolution 384 × 384 is used during fine-tuning.
They use the same pre-training dataset as (Li et al. 2021a) with:
- Two Human-annotated datasets COCO and Visual Genome (Krishna et al., 2017)
- Three web datasets Conceptual Captions (Changpinyo et al., 2021), Conceptual 12M (Changpinyo et al., 2021), SBU captions (Ordonez et al., 2011)).
Effect of CapFilt. The idea of CapFilt captioning and filtering noisy data from the web can open the door to scaling the model with higher accuracy (less noisy signal between the image-text pairs). The use of CapFilt to filter out noisy web data leads to better performance improvement across different downstream tasks, including image-text retrieval and image captioning with fine-tuned and zero-shot settings. In addition, according to the authors when only the captioner or the filter is applied to the dataset with 14M images, performance improvement can be observed.
Diversity is Key for Synthetic Captions. In CapFilt, the authors employ Nucleus sampling (Holtzman et al., 2020) ฿ to generate synthetic captions. Nucleus sampling is a stochastic decoding method, where each token is sampled from a set of tokens whose cumulative probability mass exceeds a threshold p (p = 0.9).
We can represent the top-p vocabulary as w_i~V^(p), where the V^(p) is the Top-k sampling where k changes at every time step cover p probability mass and can be written as:
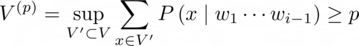
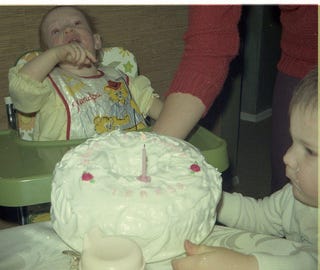
In Table 1, the authors compare it with beam search, a deterministic decoding method that aims to generate captions with the highest probability. Although, the nucleus sampling is noisier than beam search it generates a more diverse caption. Beam search generates safer captions that are common with repetition (beam search drawback) hence offering less knowledge. In short, the Nucleus sampling leads to evidently better performance, despite being noisier as suggested by a higher noise ratio from the filter as shown in Figure 10 (image), the nucleus sample generates a more diverse caption:
Beam Search k=3 : a baby sitting in a high chair eating cake
Nucleus Sampling : a baby eats his birthday cake and sits with his mom
|------------+--------+-------------------|
| Beam search vs Nucleus sampling |
|------------+--------+-------------------|
| generation | noise | Caption-FT (COCO) |
| method | ratio% | B@4 CIDEr |
|------------+--------+-------------------|
| None | NA | 38.0 127.8 |
| Beam | 19 | 38.4 128.9 |
| Nucleus | 25 | 38.6 129.7 |
|------------+--------+-------------------|
Table 1. Comparison between beam search and nucleus sampling for synthetic caption generation. Models are pre-trained on 14M images.
(better read this in the PC version)Nucleus sampling leads to evidently better performance, despite being noisier as suggested by a higher noise ratio from the filter as shown in Table 2 the result is comparable with the final beam search (Note that, the result in Table 2 is based on my run).
|---------+-------+-------+-------+-------+-------+-------+-------|
| Beam search vs Nucleus sampling COCO benchmark |
|---------+-------+-------+-------+-------+-------+-------+-------|
| model | B1 | B2 | B3 | B4 | M | C | S |
|---------+-------+-------+-------+-------+-------+-------+-------|
| Nucleus | 0.660 | 0.456 | 0.308 | 0.205 | 0.239 | 0.869 | 0.190 |
| Beam | 0.797 | 0.649 | 0.514 | 0.403 | 0.311 | 1.365 | 0.243 |
|---------+-------+-------+-------+-------+-------+-------+-------+
Table 2. Comparison between beam search and nucleus (Large model) sampling in benchmark COCO-caption dataset (Karpathy test set).The authors hypothesize that the reason is that nucleus sampling generates more diverse and surprising captions, which contain more new information that the model could benefit from. On the other hand, beam search tends to generate safe captions that are common in the dataset, hence offering less extra knowledge
Parameter Sharing and Decoupling During pre-training. The text encoder and decoder share all parameters except for the self-attention layers as shown in the main Figure 3 (same parameters have the same color).
|----------------------------+------------+--------------|
| Parameter Sharing |
|----------------------------+------------+--------------|
| Layers shared | parameters | Caption COCO |
| | | B@4 CIDEr |
|----------------------------+------------+--------------|
| All | 224M | 37.2 125.9 |
| All expect Cross Attention | 252M | 37.4 126.1 |
| All expect Self Attention | 252M | 38.0 127.8 |
| None | 361M | 37.8 127.4 |
|----------------------------+------------+--------------|
Table.3 Comparison between different parameter sharing strategies for the text encoder and decoder during pre-training. (better read this in the PC version)Table 3 shows an evaluation of the pre-trained model with different parameter sharing strategies, where pre-training is performed on the 14M images with web texts. As the result shows, sharing all layers except for Self Attention leads to better performance compared to not sharing, while also reducing the model size thus improving training efficiency. If the Self Attention layers are shared, the model’s performance would degrade due to the conflict between the encoding task and the decoding task.
|------------------+-------+--------------|
| Effect of captioner & Filter share para |
|------------------+-------+--------------|
| captioner | Noise | Caption COCO |
| & Filter | ratio | B@4 CIDEr |
|------------------+-------+--------------|
| Share parameters | 8% | 38.4 129.0 |
| Decoupled | 25% | 38.6 129.7 |
|------------------+-------+--------------|
Table.4 Comparison between different parameter sharing
strategies for the text encoder and decoder during pre-training. (better read this in the PC version)During CapFilt, the captioner and the filter are end-to-end fine-tuned individually on COCO. Table 4 shows the effect if the captioner and filter share parameters in the same way as pre-training.
Comparison with State-of-the-arts
For simplicity and following the same task I described above, I will only show a comparison result with state-of-the-art models on the image captioning task.
Image Captioning. Two datasets are considered for image captioning: NoCaps (Agrawal et al., 2019) and COCO, both evaluated using the model fine-tuned on COCO with the LM loss. Similar to Wang et al. (2022), a prompt “a picture of ” (zero-shot image captioning) is added at the beginning of each caption, which leads to slightly better results. As shown in Table 5, BLIP with 14M pre-training images substantially outperforms methods using a similar amount of pre-training data on COCO caption dataset.
The LM loss (see Figure 5) is used to fined-tuned the model to generate a caption description for an image. Also, the prompt based approach is used which led to better results (Wang et al. 2022). As shown in Table 5 BLIP with 129M images achieves competitive performance with LEMON 200M images.
|-----------------------------------+------------+---------------|
| Image captioning task |
|-----------------------------------+------------+---------------|
| Method | pre-trined | COCO caption |
| | #images | Karpathy test |
| | | B@4 C |
|-----------------------------------+------------+---------------|
| Enc-Dec (Changpinyo et al., 2021) | 15M | - 110.9 |
| VinVL (Zhang et al., 2021) | 5.7M | 38.2 129.3 |
| LEMON_base (Hu et al., 2021) | 200M | 40.3 133.3 |
|-----------------------------------+------------+---------------|
| BLIP | 14M | 38.6 129.7 |
| BLIP | 129M | 39.4 131.4 |
| BLIP | 129M | 39.7 133.3 |
|-----------------------------------+------------+---------------|
| LEMONlarge | 200M | 40.6 135.7 |
| BLIP_ViT-L | 129M | 40.4 136.7 |
|-----------------------------------+------------+---------------|
Table 5. Comparison with state-of-the-art image captioning methods on COCO Caption task. Note that, VinVL and LEMON require an object detector pre-trained on 2.5M images with human-annotated bounding boxes and high resolution (800×1333) input images. (better read this in the PC version)Also below in Table 6 a comparison included a stand-alone image captioning model (♛).
|--------------------------------------+------+-------|
| COCO-Caption (Karpathy testset) |
|--------------------------------------+------+-------|
| MODEL | B@4 | C |
|--------------------------------------+------+-------|
| Transformer (Vaswani et al., 2017) ♛ | 38.7 | 124.7 |
| AoANet (Huang et al., 2019) ♛ | 38.9 | 129.8 |
| M_2 (Cornia et al., 2020) ♛ | 39.1 | 131.2 |
| Vin_VL (Zhang et al., 2021) | 38.2 | 133.3 |
| OSCAR (Li et al., 2020) | 37.4 | 127.7 |
| LEMON (Hu et al., 2021) | 40.3 | 133.3 |
| UNIMO (Li et al., 2021)♞ | 39.6 | 127.7 |
|--------------------------------------+------+-------|
| BLIP This paper | 39.7 | 133.3 |
|--------------------------------------+------+-------|
Table 6. Comparison of different caption models on the Karpathy test including stand-alone caption generation model. ♞ please refer to my other post for more information about that model.
(better read this in the PC version)Ablation Study
In this section, this work explores the main reason for the improvement with ablation study by asking these questions:
(1) Is the effectiveness of CapFilt is due to longer training ?
Since the bootstrapped dataset contains more text than the original dataset, training for the same number of epochs takes longer with the bootstrapped dataset. To verify that the effectiveness of CapFilt is not due to longer training, a replicate version is used from the web text, in the original dataset, so that it has the same number of training samples per epoch as the bootstrapped dataset. As shown in Table 7, longer training using noisy web texts does not improve performance.
|---------+-------+--------------|
| Effectiveness of CapFilt |
|---------+-------+--------------|
| CapFilt | Texts | Caption COCO |
| | | B@4 C |
|---------+-------+--------------|
| No | 15.3M | 38.0 127.8 |
| No | 24.7M | 37.9 127.7 |
| Yes | 24.7M | 38.6 129.7 |
|---------+-------+--------------|
Table 7. The original web texts are replicated to have the same number of samples per epoch as the bootstrapped dataset. Results verify that the improvement from CapFilt is not due to longer training time. (better read this in the PC version)(2) Should a new model be trained on the bootstrapped dataset (with continue training) ?
The authors also investigate the effect of continue training from the previous pre-trained model, using the bootstrapped dataset. Table 8 shows that continue training does not help. This observation agrees with the common practice in knowledge distillation, where the student model cannot be initialized from the teacher.
|----------+--------------|
| Continue training |
|----------+--------------|
| Continue | Caption COCO |
| | B@4 C |
|----------+--------------|
| Yes | 38.5 129.7 |
| No | 38.6 129.7 |
|----------+--------------|
Table 8. Continue training the pre-trained model offers less gain compared to training a new model with the bootstrapped dataset.Conclusion
This work proposed a Visual and Language Pre-training framework (VLP)(training technique and pre-trained model) that achieves state-of-the-art performance on a wide range of downstream vision-language tasks, including understanding and generation-based tasks. In addition, they overcome three of the limitations that current state-of-the-art suffers from:
(1) The visual block relies (see Figure 2) on a pre-trained object detector to extract pre-computed features. In addition, the object detector required bounding box human annotation, which is costly. Also, the extracted feature is computationally expensive, and it is needed for any new image during the inference.
(2) The word embedding and the caption feature are extracted from different semantic spaces.
(3) The current contrastive learning method uses very noisy data collected from the web, which affects (1) the accuracy and (2) increases the model parameter/images with slightly better performance (as shown in Table 2 Lemon with 71M extra images only 0.6 improvements in B@4).
By tackling these limitations, the proposed model can be (1) easy to adapt to any downstream task; (2) required fewer training examples, with less noisy images, and higher accuracy.
Finally, to keep this short, I only discussed the Image Captioning task, and for other downstream tasks, please refer to the paper. I encourage you to check out both papers by the same authors (the previous one (Li et al. 2021a)).
References
Please refer to the original paper for the full references, figures, and formulas.
Figures OmniGraffle Pro
